Research Question
The Problem
Traditional machine learning requires centralizing all training data, which creates privacy concerns and bandwidth limitations. Federated learning trains models across distributed devices without sharing raw data.
What We Tested
Built experiments to compare model accuracy, training time, and convergence rates between federated learning and traditional centralized training across different dataset types and sizes.
Multiple Datasets
Tested on image classification, text processing, and numerical data to understand performance across different domains.
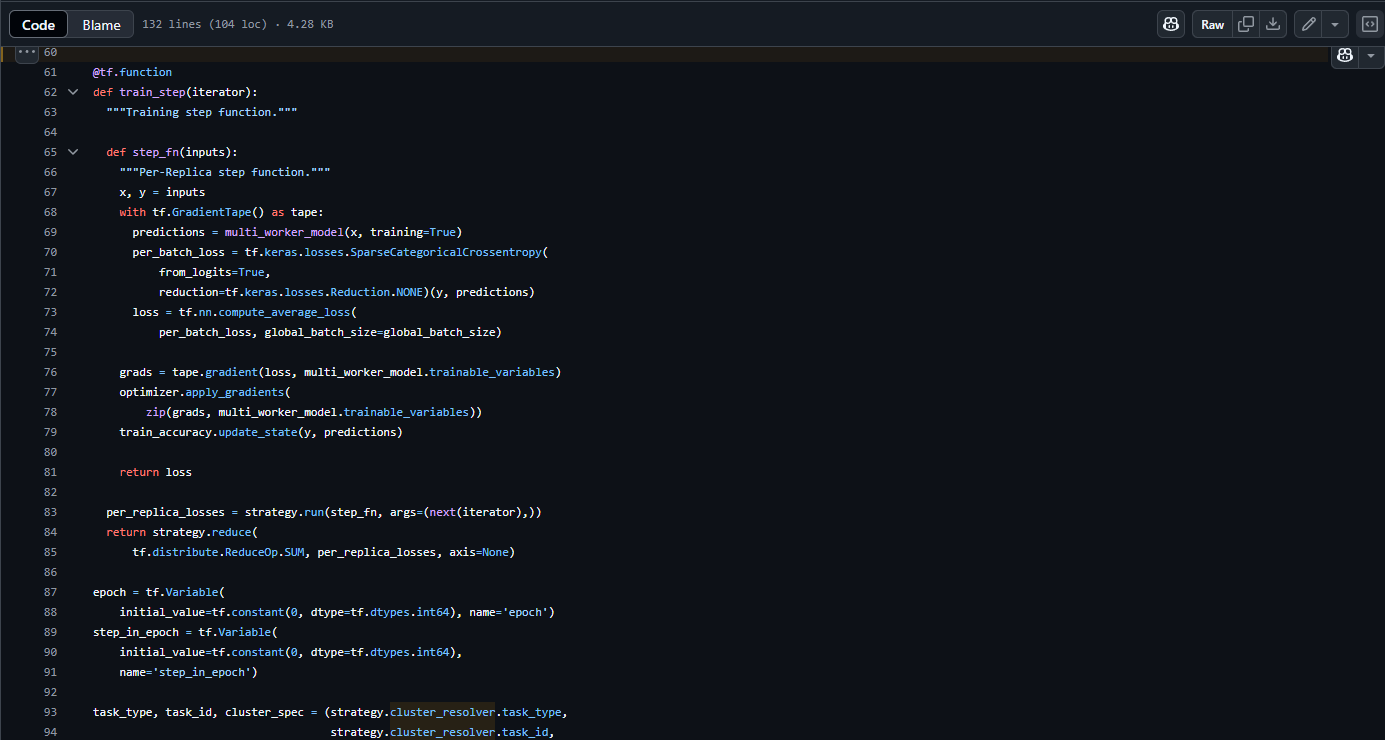
Framework Comparison
Implemented experiments in both PyTorch and TensorFlow to validate results across different ML frameworks.
Performance Metrics
Measured accuracy, training time, memory usage, and communication overhead for comprehensive analysis.